SQL Server KENDALLW_TV Function
Updated 2023-11-06 16:26:26.713000
Description
Use the table-valued function KENDALLW_TV to calculate Kendall's coefficient of concordance (w) as an index of inter-rater reliability for ordinal data. The equation for Kendall's w is:
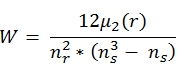
Where
r is the sum of the ranks of the ratings for all raters for each subject
µ2 is the second central moment
nr is the number of raters
ns is the number of subjects being rated
The equation for Kendall's w corrected for ties is:
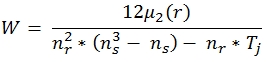
Where
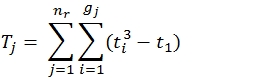
ti is a count of each rating within a rater
gj is the number of unique ratings within a rater
Syntax
SELECT * FROM [westclintech].[wct].[KENDALLW_TV](
<@InputData_RangeQuery, nvarchar(max),>
,<@CorrectTies, bit,>)
Arguments
@InputData_RangeQuery
a T-SQL statement, as a string, that specifies the subject, rater, and rating values.
@CorrectTies
a bit value identifying whether the coefficient should be corrected for ties within raters.
Return Type
table
{"columns": [{"field": "colName", "headerName": "Name", "header": "name"}, {"field": "colDatatype", "headerName": "Type", "header": "type"}, {"field": "colDesc", "headerName": "Description", "header": "description", "minWidth": 1000}], "rows": [{"id": "f904af4d-c6d0-4220-a2af-d283797bd007", "colName": "W", "colDatatype": "float", "colDesc": "the Kendall w statistic"}, {"id": "0212bcb1-83aa-437f-baa6-b642edb59ce4", "colName": "X", "colDatatype": "float", "colDesc": "the chi-squared statistic"}, {"id": "757f79b1-3e1b-4b78-b71a-c8dbc5470b76", "colName": "DF1", "colDatatype": "float", "colDesc": "the degrees of freedom"}, {"id": "e39fad02-e152-427c-8c49-7336d2fbe4d5", "colName": "P", "colDatatype": "float", "colDesc": "the p-value"}]}
Remarks
The function is insensitive to order and automatically matches all the ratings for a subject.
NULL values are excluded.
Examples
SELECT n.s,
x.rater,
x.rating
INTO #k
FROM
(
SELECT 1,
3,
3,
2
UNION ALL
SELECT 2,
3,
6,
1
UNION ALL
SELECT 3,
3,
4,
4
UNION ALL
SELECT 4,
4,
6,
4
UNION ALL
SELECT 5,
5,
2,
3
UNION ALL
SELECT 6,
5,
4,
2
UNION ALL
SELECT 7,
2,
2,
1
UNION ALL
SELECT 8,
3,
4,
6
UNION ALL
SELECT 9,
5,
3,
1
UNION ALL
SELECT 10,
2,
3,
1
UNION ALL
SELECT 11,
2,
2,
1
UNION ALL
SELECT 12,
6,
3,
2
UNION ALL
SELECT 13,
1,
3,
3
UNION ALL
SELECT 14,
5,
3,
3
UNION ALL
SELECT 15,
2,
2,
1
UNION ALL
SELECT 16,
2,
2,
1
UNION ALL
SELECT 17,
1,
1,
3
UNION ALL
SELECT 18,
2,
3,
3
UNION ALL
SELECT 19,
4,
3,
2
UNION ALL
SELECT 20,
3,
4,
2
) n(s, r1, r2, r3)
--This CROSS APPLY UNPIVOTS the input data into third normal form
CROSS APPLY
(
SELECT 'r1',
r1
UNION ALL
SELECT 'r2',
r2
UNION ALL
SELECT 'r3',
r3
) x(rater, rating);
SELECT p.*
FROM wct.KENDALLW_TV('SELECT s,rater,
rating FROM #k', 'False') k
--This CROSS APPLY UNPIVOTS the tvf columns for formatting
CROSS APPLY
(
SELECT 'W',
k.W
UNION ALL
SELECT 'X',
k.X
UNION ALL
SELECT 'df1',
k.df1
UNION ALL
SELECT 'p',
k.p
) p(stat, value_stat);
DROP TABLE #k;
This produces the following result.
{"columns":[{"field":"stat"},{"field":"k","headerClass":"ag-right-aligned-header","cellClass":"ag-right-aligned-cell"}],"rows":[{"stat":"W","k":"0.501921470342523"},{"stat":"X","k":"28.6095238095238"},{"stat":"df1","k":"19"},{"stat":"p","k":"0.072380354693757"}]}